Hvordan ved din streamingtjeneste, hvad du vil se?
Dette undervisningsmateriale omhandler de anbefalingsalgoritmer, der bl.a. bruges når streaming- og musiktjenester giver anbefalinger til brugerne.
Det lærer du
Du er klar, fordi…
Om lidt ved du også, at…
Forløbet
01. Hvad skal Lucca og Charlie se?
Streamingtjenester forsøger hele tiden at gætte, hvad deres brugere gerne vil se. Det gør de ved at kigge på, hvad man har set før, og finde film, der minder om det.
I denne opgave skal I prøve at tænke som en streamingtjeneste og komme med jeres egne bud på, hvilke film Disney+ kunne finde på at anbefale.

02. K-NN anbefalingsalgoritmen (del A)
K-NN står for k-nærmeste naboer. Det er en metode, hvor en algoritme anbefaler det, der ligner mest det, man allerede har set. Når en streamingtjeneste bruger K-NN, sammenligner den én film med mange andre og finder dem, der ligger tættest på.
Nu skal I lave jeres egen simple anbefalingsalgoritme. I starter med at give algoritmen information om en række film ved at beskrive dem med tal. På den måde kan filmene sammenlignes og placeres i et koordinatsystem, så det bliver muligt at se, hvilke film der minder mest om hinanden.
Åben opgave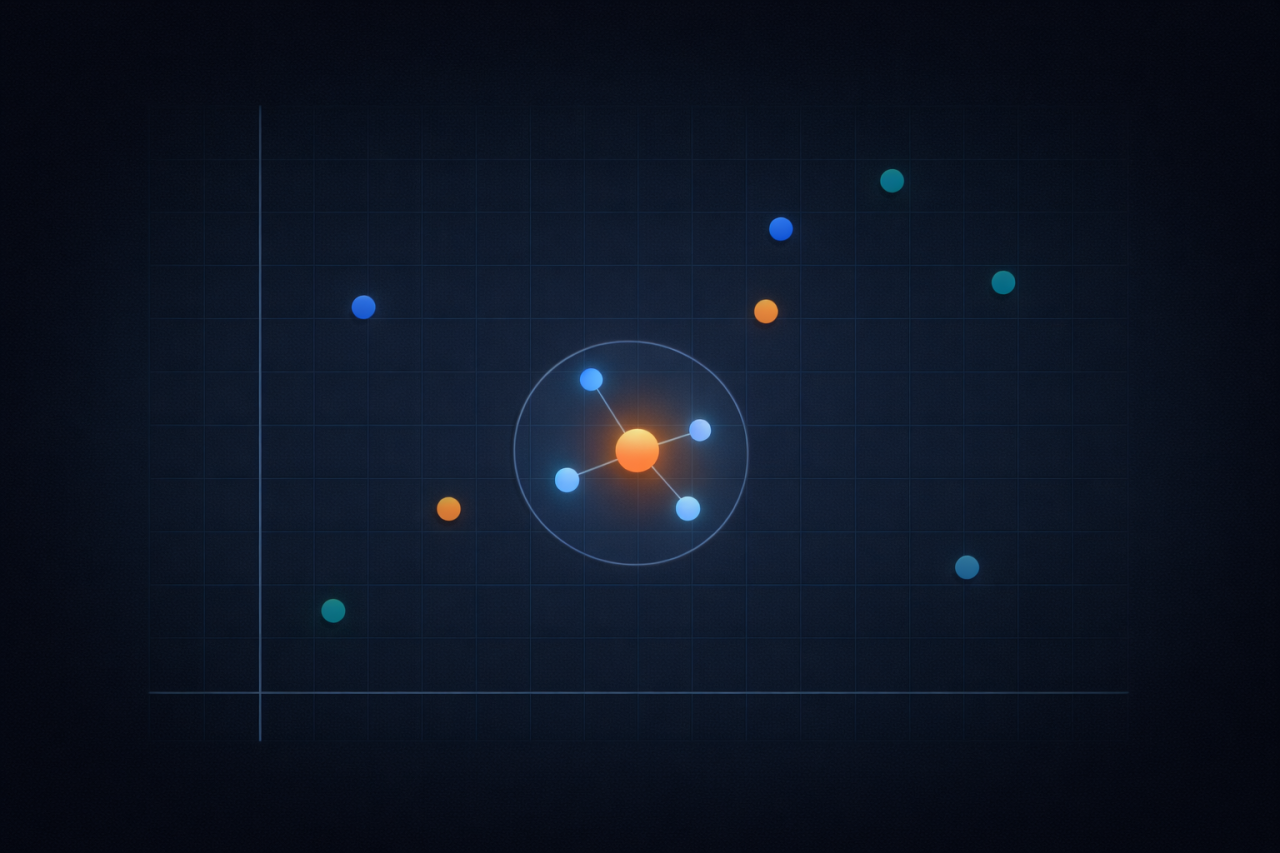
03. K-NN anbefalingsalgoritmen (del B)
K-NN står for k-nærmeste naboer. Når algoritmen har fået information om filmene, kan den bruge K-NN til at finde ud af, hvilke film der ligner mest den film, du har set. Det gør den ved at måle afstanden mellem punkterne i koordinatsystemet.
Nu skal I bruge jeres data til at lave selve anbefalingen. I vælger én film som udgangspunkt og beregner afstanden til alle de andre film. De film, der ligger tættest på, er dem, algoritmen vil anbefale.
Read more
0.4 A-NN anbefalingsalgoritmen
A-NN står for approksimative nærmeste naboer. Det er en metode, hvor algoritmen hurtigere forsøger at finde noget, der ligner – uden nødvendigvis at finde det, der ligger allertættest. I stedet arbejder den med områder eller felter og ser på, hvad der ofte ender samme sted.
Nu skal I undersøge, hvordan en A-NN-algoritme kan bruges til at lave musikanbefalinger. I vælger én sang som udgangspunkt og ser, hvilke andre sange der ofte havner i samme område. På den måde kan I finde frem til en anbefaling og vurdere, om den minder om den, man ville få ved at måle præcise afstande.
Read more